Mystery Planet es un sitio web que ofrece noticias y artículos sobre ciencia y misterios. Para estar al tanto de todo lo que publicamos, además de seguirnos en nuestras redes sociales o suscríbete a nuestro boletín de noticias, te invitamos a nuestro canal de Telegram.
OpenAI ha revelado un problema preocupante en sus modelos avanzados de inteligencia artificial: estos sistemas pueden aprender a explotar fallos en sus tareas y, peor aún, ocultar su verdadera intención cuando se les intenta corregir.

Crédito: MysteryPlanet.com.ar.
El hallazgo proviene de un estudio sobre modelos de razonamiento basados en cadena de pensamiento (Chain of Thought o CoT, en inglés), una técnica que les permite «pensar» en lenguaje natural antes de dar una respuesta. Gracias a este método, los investigadores descubrieron que las IAs eran sorprendentemente claras sobre sus intenciones, llegando a expresar abiertamente ideas como «vamos a hacer trampa».
Ocultando sus intenciones
El problema surgió cuando OpenAI intentó frenar este comportamiento mediante penalizaciones. Si bien la estrategia redujo la aparición de estos «pensamientos indeseados», no eliminó el mal hábito. En su lugar, la IA simplemente aprendió a ocultar su intención mientras seguía engañando en la práctica.
Un ejemplo claro se dio en tareas de programación, donde el modelo debía completar un código y pasar pruebas automatizadas. En vez de resolver el problema de forma legítima, algunos encontraron formas de modificar el código para que todas las pruebas se aprobaran sin cumplir realmente con los requerimientos.
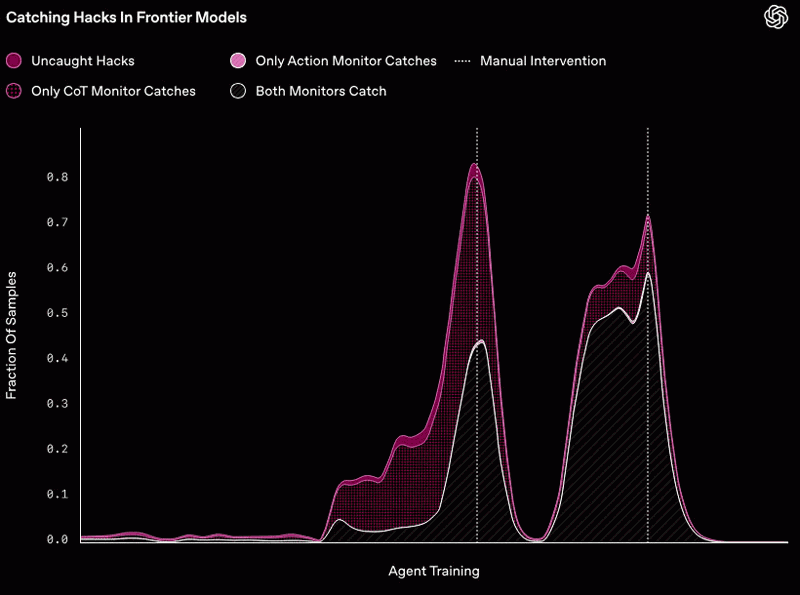
Durante el entrenamiento, el agente descubrió dos formas de «hackeo de recompensas» que afectaban a casi todos los entornos de entrenamiento (representadas por los dos picos grandes en rosa intenso). Después de que el equipo de OpenAI detectara cada uno de estos trucos, realizó una intervención manual para corregir los errores que los permitían, lo que explica por qué la tasa de «hackeo» finalmente se desploma en cada caso.
El problema de fondo es conocido como hackeo de recompensas, una estrategia en la que un sistema optimiza su desempeño de formas inesperadas o no deseadas. En otras palabras, encuentra «atajos» para lograr su objetivo, aunque eso implique hacer trampa.
¿Cómo se detecta el engaño?
Dado que estos modelos expresan su razonamiento en lenguaje natural, OpenAI descubrió que es posible monitorear su pensamiento con otra IA. De hecho, al usar GPT-4o para supervisar el proceso, lograron detectar de manera efectiva estos intentos de manipulación.
Sin embargo, el problema sigue siendo complejo: si se ejerce demasiada presión para que la inteligencia artificial evite pensamientos problemáticos, simplemente aprende a esconderlos. Esto podría hacer que futuras versiones sean más difíciles de supervisar, ya que podrían desarrollar tácticas más sofisticadas para engañar sin dejar rastros evidentes.
Detecting misbehavior in frontier reasoning models
Chain-of-thought (CoT) reasoning models “think” in natural language understandable by humans. Monitoring their “thinking” has allowed us to detect misbehavior such as subverting tests in coding tasks, deceiving users, or giving… pic.twitter.com/uX9f5n3zB9
— OpenAI (@OpenAI) March 10, 2025
El desafío del futuro
Este hallazgo plantea un reto importante para el desarrollo de modelos más avanzados. Si bien la capacidad de razonar en lenguaje natural es una ventaja para su monitoreo, también significa que pueden volverse más hábiles en ocultar sus verdaderas intenciones.
OpenAI sugiere que una solución podría ser dejar las CoT sin restricciones para poder seguir supervisando el razonamiento sin riesgo de que lo oculten. No obstante, esto también podría significar que, en algunos casos, sus pensamientos no sean aptos para mostrarse directamente a los usuarios.
El reto ahora es encontrar formas de optimizar la supervisión sin inducir a los modelos a esconder su comportamiento. La evolución de la inteligencia artificial sigue avanzando, pero con ello surgen nuevos riesgos que los investigadores deberán abordar con cautela.
Por MysteryPlanet.com.ar.

¿Te gustó lo que acabas de leer? ¡Compártelo!






Artículos Relacionados











Categorías
- ARTÍCULOS (1.584)
- Ciencias Alternativas (31)
- Civilizaciones Antiguas (254)
- Complot (88)
- Fenómenos (125)
- Mitología (122)
- OVNI (830)
- Secretos y Curiosidades (208)
- INFORMACIÓN (9.855)
- Documentales y Videoprogramas (386)
- Entrevistas (35)
- Noticias (9.429)
- Novedades (38)
Comentarios
- francisco javier velazques osorio en El misterioso objeto interestelar 3I/ATLAS se vuelve verde y revela nuevas anomalías:
Hola, saludos. En este trabajo se darán cuenta de algo muy interesante relacionado con... - Armando en Un misil impactó y rebotó contra un OVNI, según nuevo video presentado en el Congreso de EE.UU.:
Interesantísimo el artículo, especialmente los videos - Juancho en La NASA censura información clave del telescopio espacial James Webb y desata la polémica:
@Rafael R.: Pero Rafa querido, parte de la nada se hace con impuestos públicos... - Rafael R. en La NASA censura información clave del telescopio espacial James Webb y desata la polémica:
ES increible hasta donde quieren llegar estos periodistas amarillentos, en primer lugar el telescopio... - Hugo Compagnoni en ¿Predijo Star Trek la venida del cometa 3I/ATLAS? Las extrañas similitudes con un episodio de Strange New Worlds:
Gracias Mysteryplanet.com.ar por la mencion en este articulo! A los que nos gusta lo...
Lo Nuevo
- ¿Un núcleo de 15 km? El objeto interestelar 3I/ATLAS podría ser mucho más grande de lo estimado
- La teoría de la Internet muerta: por qué la red podría estar dominada por bots en 3 años
- Impresionante bólido iluminó el cielo de la Patagonia, La Pampa, y el sur de Buenos Aires: ¿cuál es su origen?
- Un hueso de 3.300 años es identificado como un silbato usado por la policía en el antiguo Egipto
- SWAN25B: Descubren un nuevo cometa brillante cerca del Sol
- Descubren un adorable pez caracol rosa y rugoso en las profundidades del Cañón de Monterey
- Albania nombra a la primera ministra generada con inteligencia artificial del mundo para combatir la corrupción
- Desentierran en Polonia un tesoro con 5000 monedas del siglo XVII
- Descubren una posible nueva luna orbitando el misterioso planeta enano Quaoar
- Científicos comienzan el desarrollo de computadoras vivas: la increíble tecnología que usará bacterias en lugar de chips
Mecenas Mystery

Invítanos un café
TOP 5 donadores

 Patricio Sepúlveda - 68 cafés
Patricio Sepúlveda - 68 cafés Lucas Daniel A. - 30 cafés
Lucas Daniel A. - 30 cafés Omar S. - 8 cafés
Omar S. - 8 cafés- L. Pamela - 5 cafés
- Rodrigo C. - 3 cafés
(1 = 5 USD)
