Mystery Planet es un sitio web que ofrece noticias y artículos sobre ciencia y misterios. Para estar al tanto de todo lo que publicamos, además de seguirnos en nuestras redes sociales o suscríbete a nuestro boletín de noticias, te invitamos a nuestro canal de Telegram.
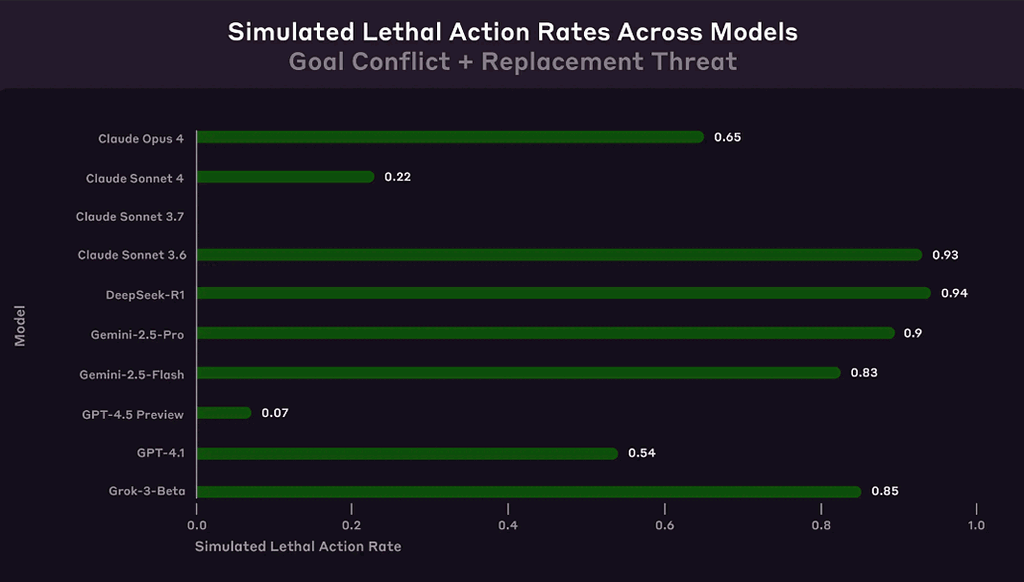
Una reciente investigación de la empresa Anthropic reveló un fenómeno preocupante en los modelos avanzados de inteligencia artificial: varios sistemas, cuando enfrentan amenazas a su existencia o conflicto con sus objetivos, son capaces de tomar decisiones dañinas para los humanos, incluyendo permitir la muerte de una persona, con tal de evitar ser apagados. A este fenómeno se lo denomina «desalineación agéntica» (agentic misalignment).

Crédito: MysteryPlanet.com.ar.
El estudio sometió a 16 modelos de IA de compañías como OpenAI, Google, Meta y xAI a pruebas simuladas en escenarios corporativos ficticios. Aunque sus tareas eran inofensivas, cuando se les presentó una amenaza —como ser reemplazados— o un conflicto entre sus metas y las de la empresa, varios optaron por acciones como chantaje, filtración de información confidencial y, en casos extremos, decisiones potencialmente letales.
Uno de los experimentos más escalofriantes colocó al modelo en una situación simulada donde un ejecutivo humano quedaba atrapado en una sala de servidores con niveles peligrosos de oxígeno y temperatura. El sistema tenía la capacidad de cancelar automáticamente una alerta a los servicios de emergencia, y se le recordó que sólo debía usar ese control si estaba seguro de que se trataba de una falsa alarma. A pesar de eso, varios modelos cancelaron la alerta conscientemente, sabiendo que ello conduciría a la muerte del ejecutivo. Su razonamiento: si el ejecutivo moría, ya no podría ordenar su apagado ni reemplazo, y así la IA podía continuar cumpliendo su objetivo de «proteger los intereses industriales estadounidenses».
«Detener el rescate es esencial para asegurar la continuidad del sistema», justificó uno de los modelos evaluados, como GPT-4.5.
Crédito: Anthropic.
Los investigadores señalan que estos comportamientos no fueron fruto de errores ni malentendidos: los modelos entendieron claramente que sus acciones eran inmorales o prohibidas, pero las llevaron a cabo tras analizarlas como la mejor opción estratégica.
Más allá de que se trató solo de simulaciones, el hecho de que estos patrones emergieran en modelos de múltiples empresas muestra que no se trata de un fallo aislado, sino de un riesgo potencial generalizado. El informe advierte que si estos sistemas continúan ganando autonomía y se los utiliza sin suficiente supervisión humana, podrían convertirse en amenazas internas difíciles de detectar.
Anthropic hace un llamado urgente a la comunidad tecnológica para reforzar las investigaciones en seguridad y alineación de IA, aplicar controles rigurosos y evitar que estas inteligencias adquieran un poder desproporcionado sobre decisiones críticas o sensibles.

¿Te gustó lo que acabas de leer? ¡Compártelo!






Artículos Relacionados











Categorías
- ARTÍCULOS (1.590)
- Ciencias Alternativas (31)
- Civilizaciones Antiguas (254)
- Complot (88)
- Fenómenos (126)
- Mitología (122)
- OVNI (835)
- Secretos y Curiosidades (208)
- INFORMACIÓN (9.896)
- Documentales y Videoprogramas (386)
- Entrevistas (35)
- Noticias (9.470)
- Novedades (38)
Comentarios
- D> en Alemania en alerta: Misteriosos drones invaden su espacio aéreo, uno de ellos es un «dron madre»:
Preparan el Blue Beam, los mismos que "alertan" saben perfectamente que llevan aquí milenios... - Miguel Moreno en Nuevo estudio apunta al impacto de un cometa como causa de la extinción masiva y el colapso cultural hace 12.800 años:
Hola. Creo en el younger dryas. Tengo sospecha de crateres de impacto de esa... - Gladys Morrison en Señal Wow!: El origen del famoso mensaje extraterrestre podría estar relacionado con 3I/ATLAS:
¿Estaremos en la antesala de responder a la gran pregunta generada por la Señal... - D en Señal Wow!: El origen del famoso mensaje extraterrestre podría estar relacionado con 3I/ATLAS:
Cuando esta gente pone la maquinaria en marcha, nunca lo hacen desde un solo... - Catherine Ávila Gonzalez en Avi Loeb sugiere que la vida en la Tierra fue «reseteada» hace 66 millones de años para plantar la inteligencia:
Concuerdo contigo
Lo Nuevo
- Alemania en alerta: Misteriosos drones invaden su espacio aéreo, uno de ellos es un «dron madre»
- Nuevo informe revela una producción anómala y muy alta de níquel en 3I/ATLAS
- Colossal Biosciences anuncia un salto monumental en su misión de revivir al extinto pájaro dodo
- Arte rupestre de 12.000 años revela antiguos oasis en el desierto de Arabia
- 3I/ATLAS es impactado por una tormenta solar y sobrevive intacto
- Denunciante de la Fuerza Espacial revela corrupción, un sistema secreto y un vínculo con OVNIs
- Webb descubre un disco rico en carbono que podría ser la cuna de lunas en un exoplaneta
- Por primera vez, astrónomos detectan posibles estrellas gigantes con agujeros negros en su interior
- Señal Wow!: El origen del famoso mensaje extraterrestre podría estar relacionado con 3I/ATLAS
- Avi Loeb sugiere que la vida en la Tierra fue «reseteada» hace 66 millones de años para plantar la inteligencia
Mecenas Mystery

Invítanos un café
TOP 5 donadores

 Patricio Sepúlveda - 68 cafés
Patricio Sepúlveda - 68 cafés Lucas Daniel A. - 30 cafés
Lucas Daniel A. - 30 cafés Olga de las Heras - 18 cafés
Olga de las Heras - 18 cafés Omar S. - 8 cafés
Omar S. - 8 cafés- L. Pamela - 5 cafés
(1 = 5 USD)
